"A common theme in linear compression and feature extraction is to map a high dimensional vector
Flakqfqbq
Answered question
2022-05-07
Can anyone elaborate why PCA is a sub-optimal special case of mutual information maximisation ?
Answer & Explanation
nelppeazy9v3ie
Beginner2022-05-08Added 22 answers
If we just go for PCA it will optimize subspaces looking for dimensions of highest L2 norm in different senses, but if our noise has higher L2-norm than functions of interest it will rather select noise than functions of interest! And we know that independently sampled uncorrelated noise will have very low mutual information with just about anything deterministic of interest.
Therefore we will do better if we search for a method which does not focus so much on norm of actual signal/function but on some statistical correspondence like... for example, cross correlation or covariance.
New Questions in High school geometry
The distance between the centers of two circles C1 and C2 is equal to 10 cm. The circles have equal radii of 10 cm.
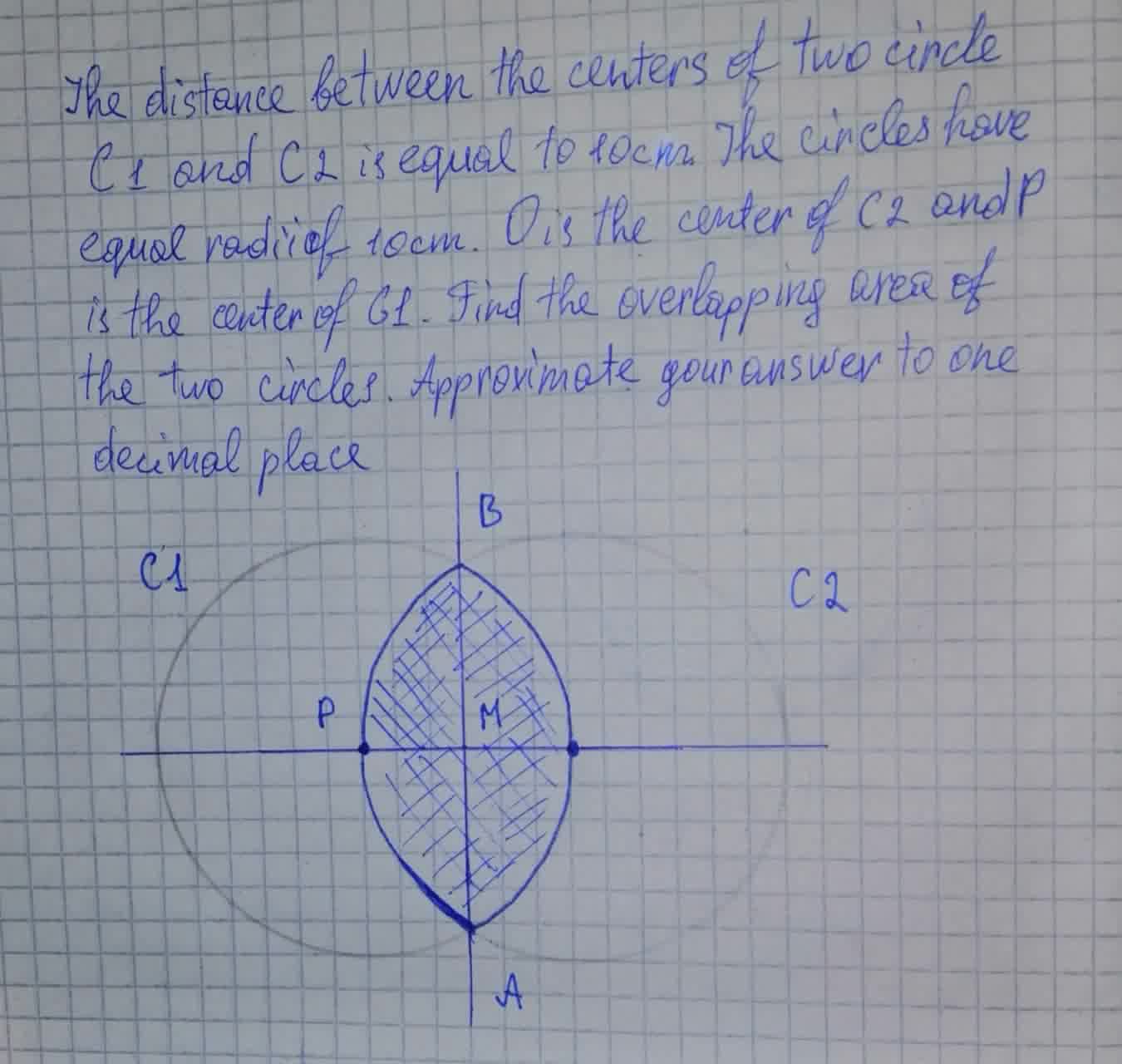
A part of circumference of a circle is called
A. Radius
B. Segment
C. Arc
D. SectorThe perimeter of a basketball court is 108 meters and the length is 6 meters longer than twice the width. What are the length and width?
What are the coordinates of the center and the length of the radius of the circle represented by the equation ?
Which of the following pairs of angles are supplementary?
128,62
113,47
154,36
108,72What is the surface area to volume ratio of a sphere?
An angle which measures 89 degrees is a/an _____.
right angle
acute angle
obtuse angle
straight angleHerman drew a 4 sided figure which had only one pair of parallel sides. What could this figure be?
Trapezium
Parallelogram
Square
RectangleWhich quadrilateral has: All sides equal, and opposite angles equal?
Trapezium
Rhombus
Kite
RectangleKaren says every equilateral triangle is acute. Is this true?
Find the number of lines of symmetry of a circle.
A. 0
B. 4
C. 2
D. InfiniteThe endpoints of a diameter of a circle are located at (5,9) and (11, 17). What is the equation of the circle?
What is the number of lines of symmetry in a scalene triangle?
A. 0
B. 1
C. 2
D. 3How many diagonals does a rectangle has?
A quadrilateral whose diagonals are unequal, perpendicular and bisect each other is called a.
A. rhombus
B. trapezium
C. parallelogram