For what class of functions is steepest descent guaranteed to converge in finite number of iterations? Is there any classification of R^n rightarrow R functions with respect to finite convergence of steepest descent (and similar first-order methods, e.g., nonlinear conjugate gradients)?
mxty42ued
Answered question
2022-11-16
Is there any classification of functions with respect to finite convergence of steepest descent (and similar first-order methods, e.g., nonlinear conjugate gradients)?
By finite convergence I mean that algorithm reaches a point with after a finite number of iterations, given that no round-off errors occur (and maybe assuming that line search is exact).
It is known that algorithms are globally convergent, i.e. , but there is no guarantee that it happens for finite k.
For example, conjugate gradient method is guaranteed to converge in n steps for positive definite quadratic functions. Are there any similar results for steepest descent?
What about (strongly) convex general functions? I was only able to find results of the type
to achieve , where f is smooth convex and x∗ is a stationary point.
As far as I understand, it does not imply finite convergence for . Is it known that finite convergence does not happen even for strongly convex functions?
Answer & Explanation
Gilbert Petty
Beginner2022-11-17Added 23 answers
Steepest descent method:
with
and
This method also ends after finally many steps for quadratic functions with A positive definite and symmetric with the following choice for :
with being Eigenvalues of A.
Step 2
However, this is not used in practice because calculating the eigenvalues of A is usually computationally much harder than solving (solving corresponds to setting the gradient of f(x) zero and thus finding the critical points. Since A is positive definite a critical point will be optimal).
New Questions in Algebra I
Find the volume V of the described solid S
A cap of a sphere with radius r and height h.
V=??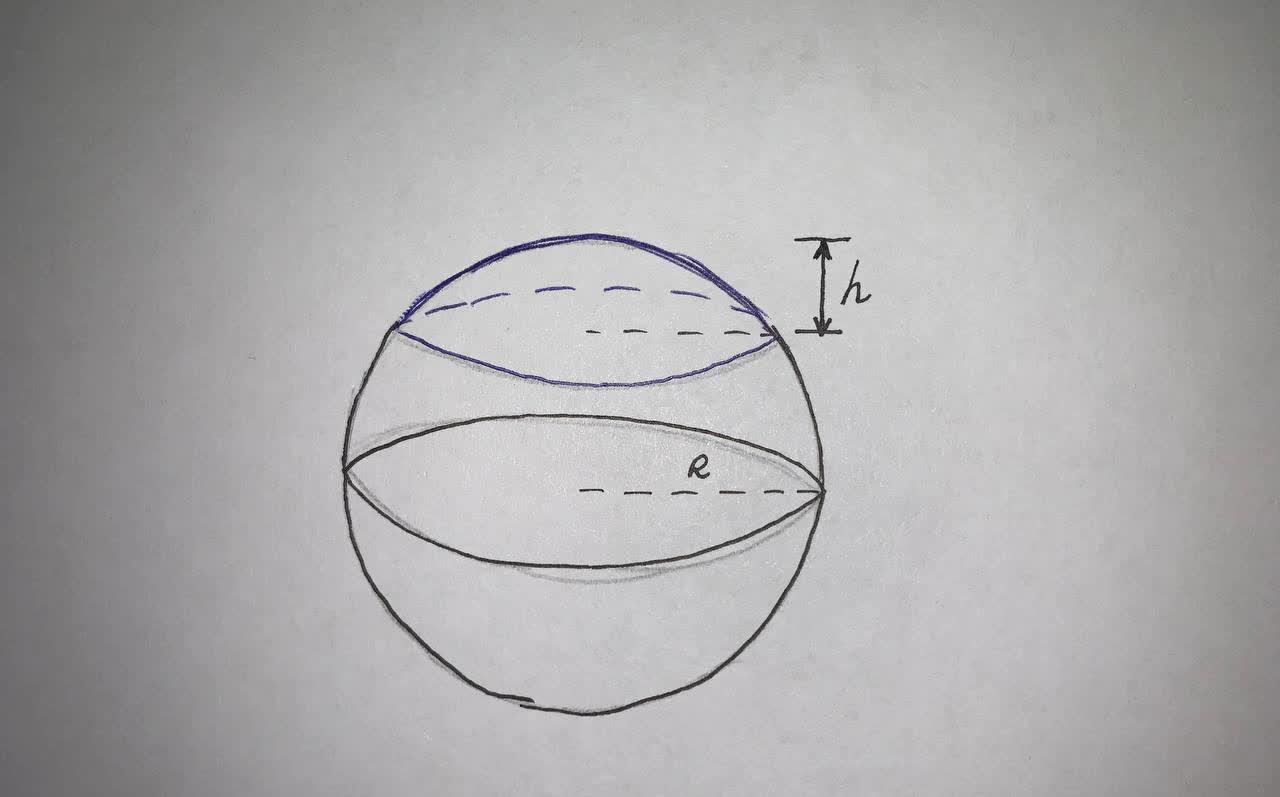
Whether each of these functions is a bijection from R to R.
a)
b)
c)
?In how many different orders can five runners finish a race if no ties are allowed???
State which of the following are linear functions?
a.
b.
c.
d.Three ounces of cinnamon costs $2.40. If there are 16 ounces in 1 pound, how much does cinnamon cost per pound?
A square is also a
A)Rhombus;
B)Parallelogram;
C)Kite;
D)none of theseWhat is the order of the numbers from least to greatest.
,
,
,
Write the numerical value of
Solve for y. 2y - 3 = 9
A)5;
B)4;
C)6;
D)3How to graph ?
How to graph using a table?
simplify
How to find the vertex of the parabola by completing the square ?
There are 60 minutes in an hour. How many minutes are there in a day (24 hours)?
Write 18 thousand in scientific notation.